日志分析与排障指南
日志能帮你做什么
监控分析告诉你"系统是否正常",日志分析告诉你在"具体发生了什么"。当用户反馈"页面打不开"或"接口返回 500"时,你需要日志来回答:
- 请求有没有到达负载均衡?
- 请求被哪条分发规则匹配了?转发到了哪台后端服务器?
- 后端服务器返回了什么状态码?耗时多少?
- 客户端是什么浏览器?从哪个地区访问的?是否通过 SSL 加密?
矩尺平台提供两种日志方式,各有用处:
| 方式 | 位置 | 用途 |
|---|---|---|
| 日志中心(内置) | 虚拟服务详情 → 日志标签 | 图形化分析、快速排障、客户端全景洞察 |
| Syslog 外发 | 各转发引擎管理页 → 日志管理 | 对接外部日志平台(ELK、Splunk 等)、长期归档 |
方式一:日志中心(内置图形化分析)
开启日志
日志中心需要在每条分发规则上单独开启。入口:【SLB 本地负载 → 分发规则 → 四层分发规则/七层分发规则】,编辑目标规则:
| 配置项 | 说明 |
|---|---|
| 存储到日志中心 | 总开关。开启后,命中此规则的请求日志才会被记录 |
| 记录全部 HTTP 头部(仅七层分发规则具有) | 开启后记录完整的 HTTP 请求和响应头部。日志量会显著增加,但对排查协议类问题(如 Header 丢失、Cookie 异常)非常有用 |
| 每秒上报日志数 | 限制每秒最大日志条数,超出部分直接丢弃不记录。这是保护机制——防止日志量过大影响转发性能。建议根据业务 QPS 设置合理阈值 |
按需开启,避免日志洪水
不需要对所有分发规则都开日志。例如:/api/ 的高频接口可以不开(或设置较低的上报阈值),/admin/ 的管理后台可以全量开启。通过分发策略精准控制——只在需要排障的规则上打开日志开关,其余规则保持关闭。
查看日志详情
入口:选中虚拟服务 → 详情 → "日志" 标签。
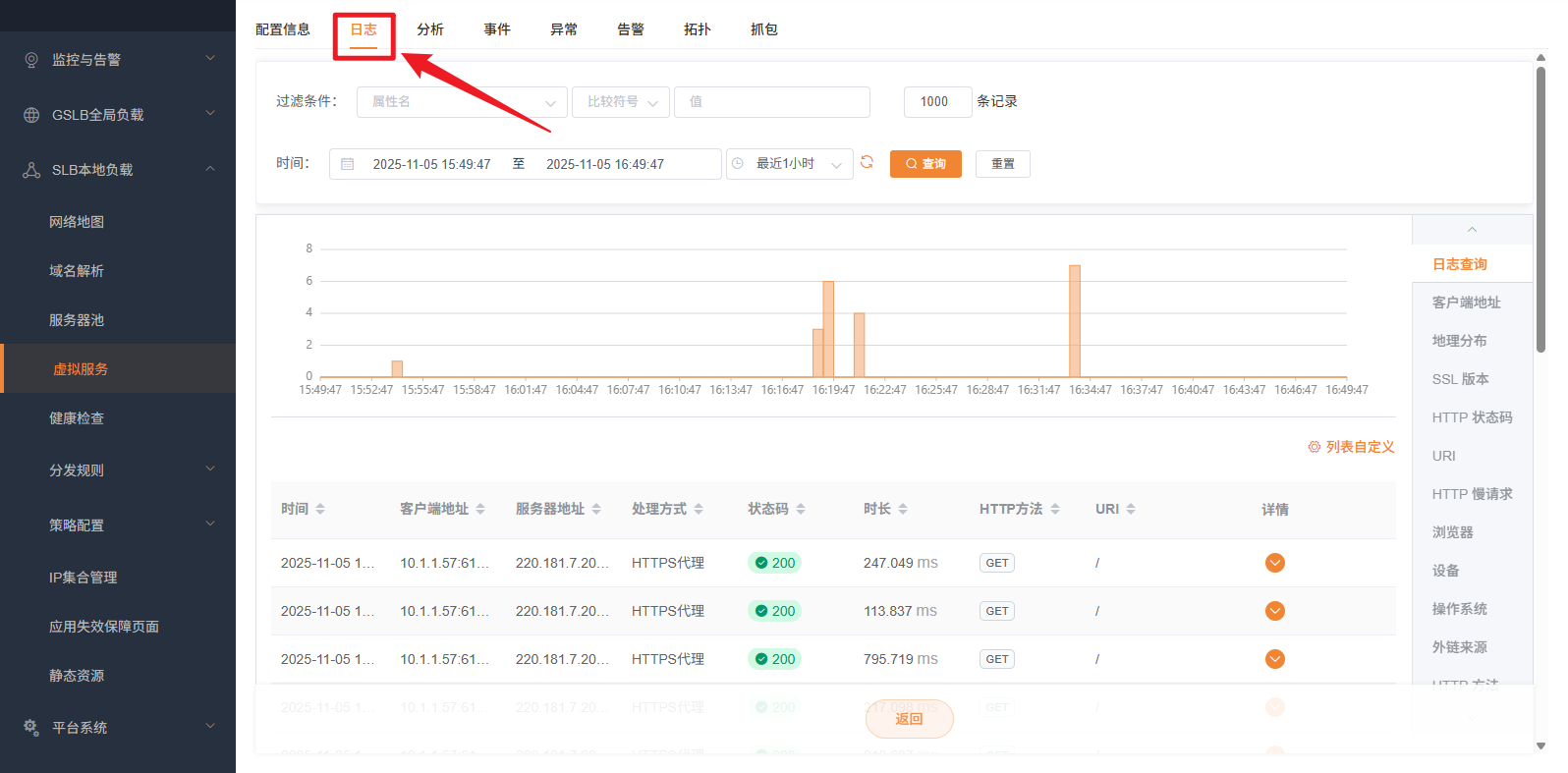
日志列表支持按时间范围和多种过滤条件查询。顶部柱状图展示时间段内的日志量分布,点击柱子可钻取到该时间段的具体日志。
点击某条日志的"详情",可查看单条请求的完整链路信息:
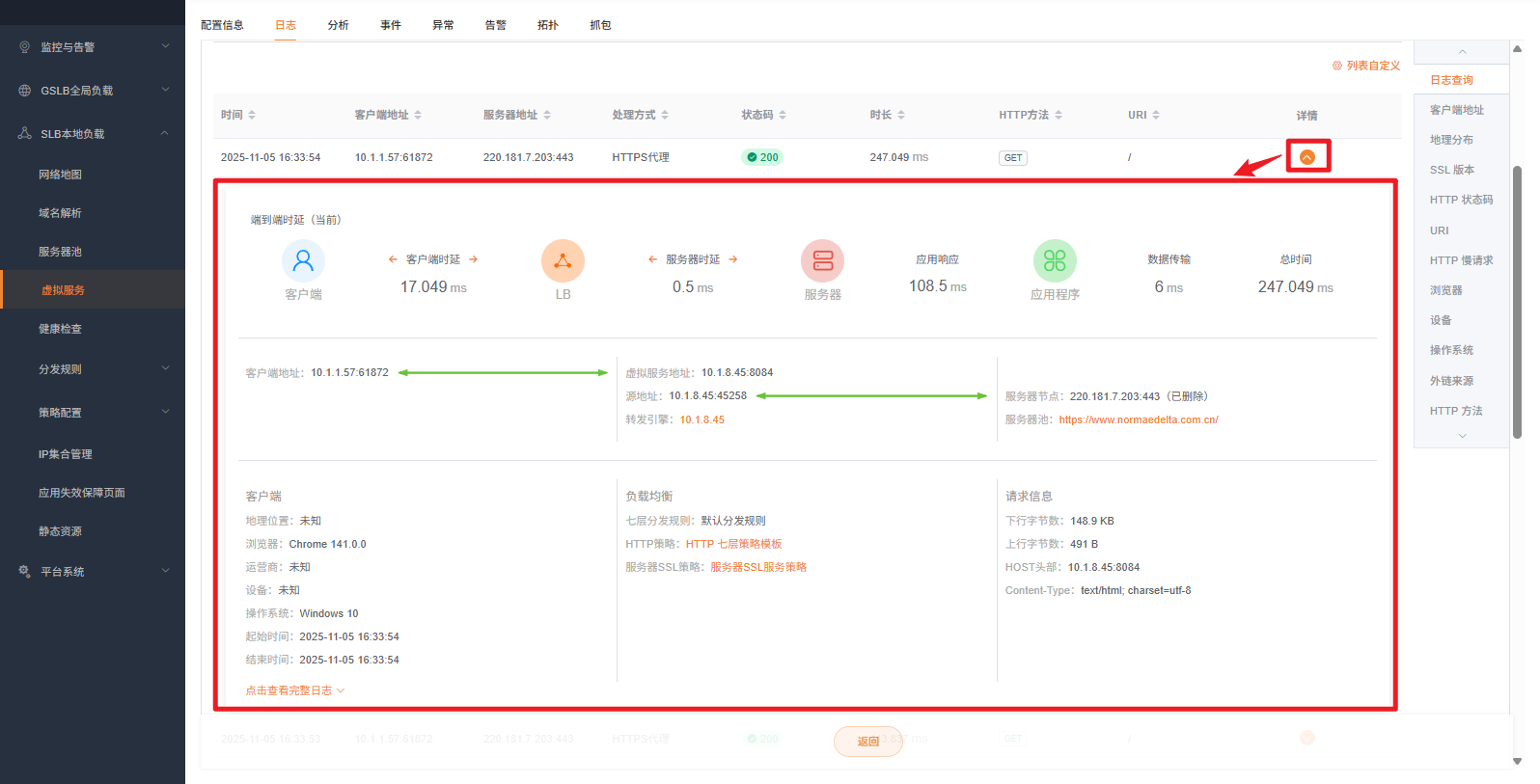
详情中高亮文字可点击跳转至关联资源(如服务器池、转发引擎)。
单条日志的核心字段:
| 字段分类 | 包含内容 | 排障用途 |
|---|---|---|
| 客户端信息 | 客户端 IP、端口、地理位置、浏览器类型、操作系统、设备类型 | 定位"谁在访问" |
| 请求信息 | HTTP 方法、URL、Host、Header、请求包体大小 | 还原"请求长什么样" |
| SSL 信息 | SSL 版本、加密套件 | 确认加密通道是否正常 |
| 虚拟服务信息 | 虚拟服务名称、监听 IP:端口 | 确认"请求进入了哪个入口" |
| 分发规则 | 命中的分发规则名称 | 确认"请求走了哪条规则" |
| 后端信息 | 服务器池名称、服务器节点 IP:端口 | 确认"请求被转发到了哪里" |
| 响应信息 | HTTP 状态码、响应时长、响应包体大小 | 判断"后端返回了什么" |
| 转发引擎 | 处理请求的转发引擎 IP | 定位"哪台引擎处理的" |
记录全部 HTTP 头部:排障利器
当遇到以下问题时,记录全部 HTTP 头部 可以帮你快速定位:
- 后端说"没收到某个 Header" → 日志中确认请求头部是否有该 Header
- Cookie 丢失/异常 → 日志中查看完整的 Cookie 内容
- CORS 跨域问题 → 查看 Origin 和 Access-Control-* 头部
- 认证失败 → 查看 Authorization 头部是否被正确转发
- 移动端/PC 端兼容问题 → 通过 User-Agent 头部定位
客户端全景分析
在日志列表右侧菜单,可切换到多个全景分析视图,从不同维度洞察客户端访问规律:
基础维度:
| 分析视图 | 展示内容 | 排障用途 |
|---|---|---|
| 客户端地址 | 访问量 Top 客户端 IP | 发现异常流量源(如某个 IP 访问量暴增) |
| 地理分布 | 按国家/地区统计访问量 | 定位区域性问题(如"某地区用户反馈慢") |
| SSL 版本 | TLS 1.2/1.3/国密的分布比例 | 确认加密协议使用情况,排查旧版客户端兼容问题 |
| HTTP 状态码 | 2xx/3xx/4xx/5xx 分布 | 一目了然看错误率,点击某个状态码钻取详情 |
| URI | 访问量 Top URI | 发现高频接口、定位"哪个接口 4xx 最多" |
| HTTP 慢请求 | 响应时间超长的请求列表 | 直接定位性能瓶颈 |
| 浏览器 | Chrome/Safari/Firefox 等分布 | 排查浏览器特定 Bug |
| 设备 | 桌面端/移动端/平板分布 | 判断流量来源设备类型 |
| 操作系统 | Windows/macOS/iOS/Android 分布 | 辅助定位 OS 特定问题 |
| 外链来源 | Referrer 来源统计 | 了解流量从哪里来 |
| HTTP 方法 | GET/POST/PUT/DELETE 分布 | 确认 API 调用方式分布 |
| 可信网关 | 经过可信代理的请求统计 | 配合 XFF 溯源 |
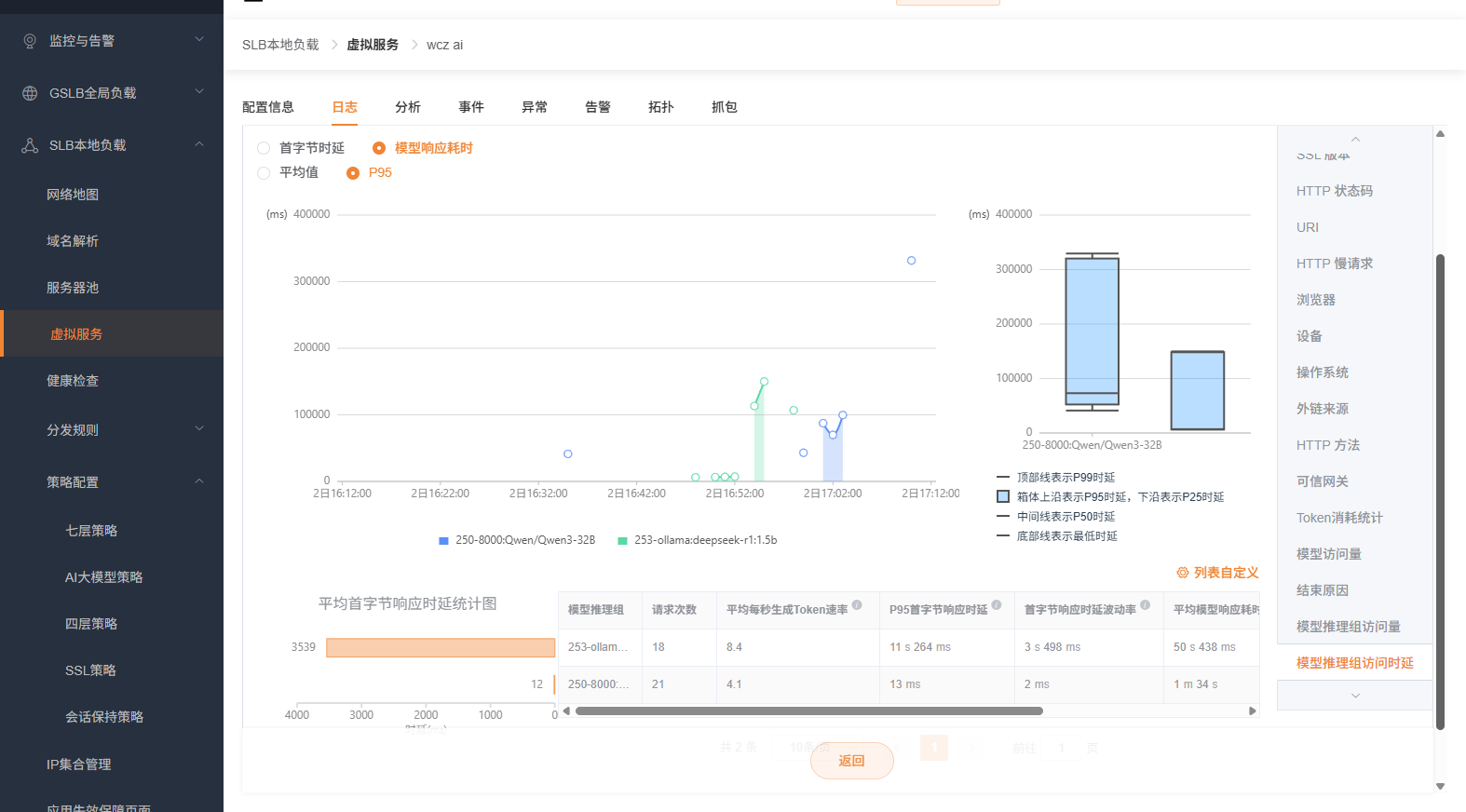
AI 虚拟服务专属日志视图
当虚拟服务开启了 AI 模式后,日志标签下会额外出现以下专属分析视图:
| 分析视图 | 展示形式 | 排障用途 |
|---|---|---|
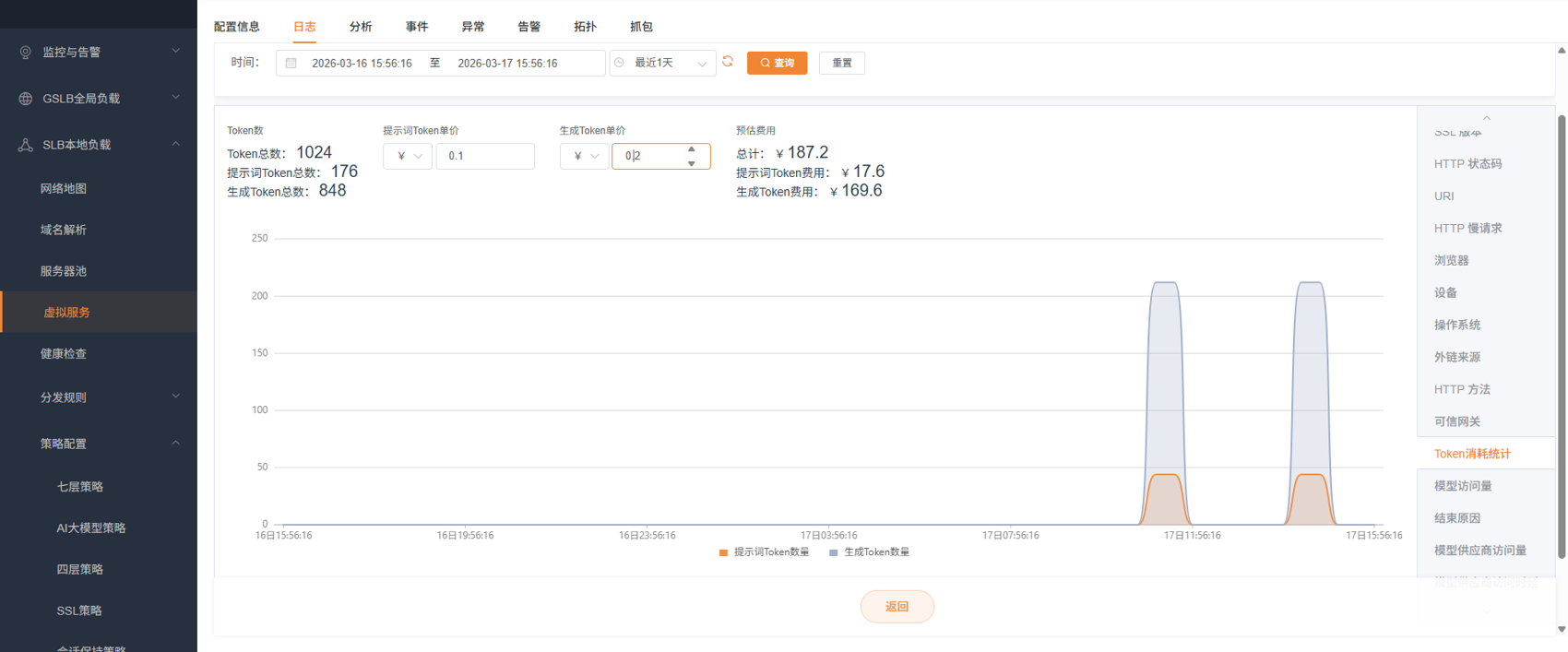
| Token 消耗统计 | 折线图:提示词 Token + 生成 Token 随时间变化 | 监控大模型调用成本,支持输入单价自动计算金额 |
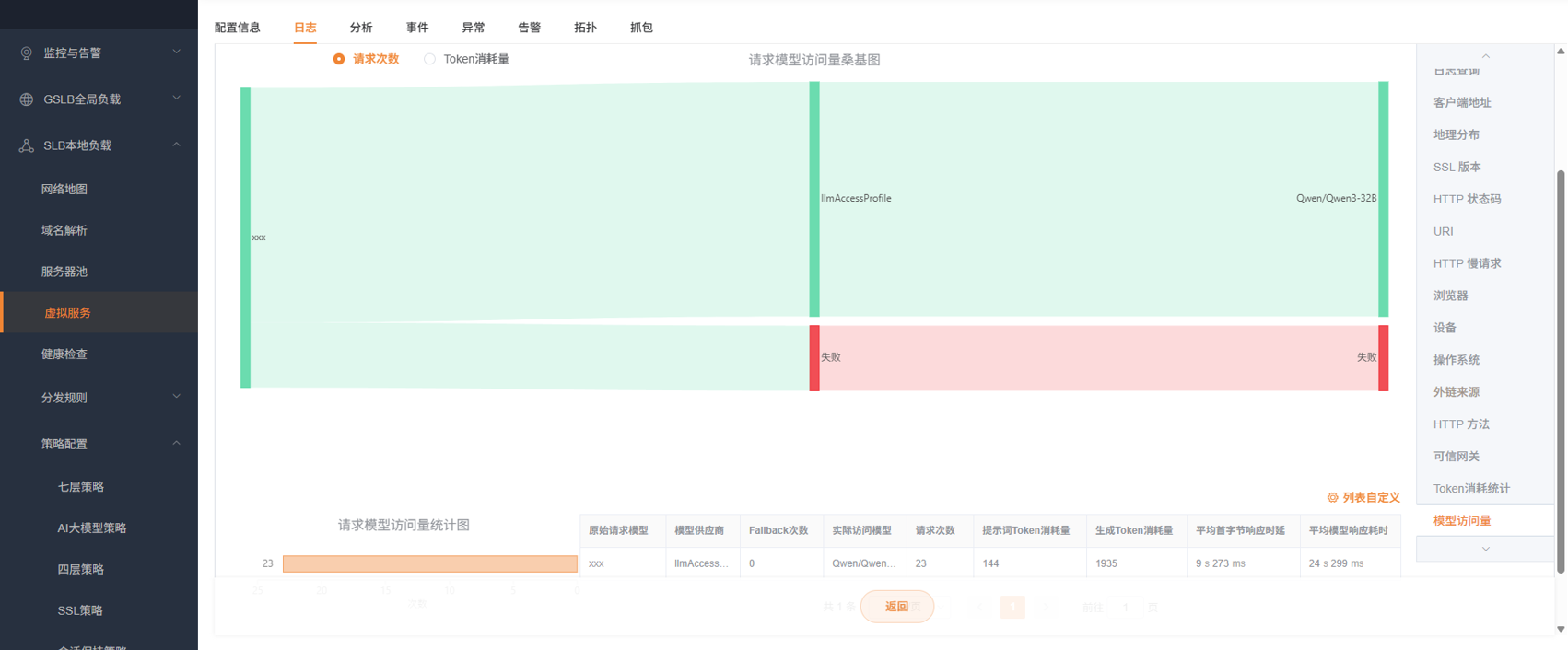
| 模型访问量 | 桑基图:用户请求模型 → 推理组 → 实际请求模型 | 追踪模型请求的完整链路,发现推理组路由异常 |
| 结束原因 | 环形图:Stop / Tool_calls / Function_call 等占比 | 判断大模型调用成功率(Stop+Tool_calls+Function_call = 成功) |
| 模型推理组访问量 | 折线图(各推理组访问量 / Token 生成速率)+ 环形图(占比) | 确认流量在各推理组间是否均衡 |
| 模型推理组访问时延 | 折线图(首字节时延 / 模型响应耗时,平均值或 P95)+ 箱型图(最低/P25/P50/P95/P99) | 定位"哪个推理组慢"、确认长尾延迟 |
方式二:Syslog 外发到外部系统
适用场景
- 已搭建 ELK、Splunk、Graylog 等日志平台,需要将矩尺日志统一汇入
- 需要长期归档日志(合规审计)
- 需要在外部平台做跨系统的日志关联分析
配置方式
Syslog 外发是每个转发引擎独立配置的——在每台转发引擎的【单台设备管理 → 日志管理】中分别设置。
为什么是每个引擎单独配? 如果所有引擎都往同一个 Syslog 服务器 IP 发,多台引擎的日志混在一起难以区分来源。每台引擎可配置不同的 Syslog 标签(Tag),外部日志平台据此区分来源。
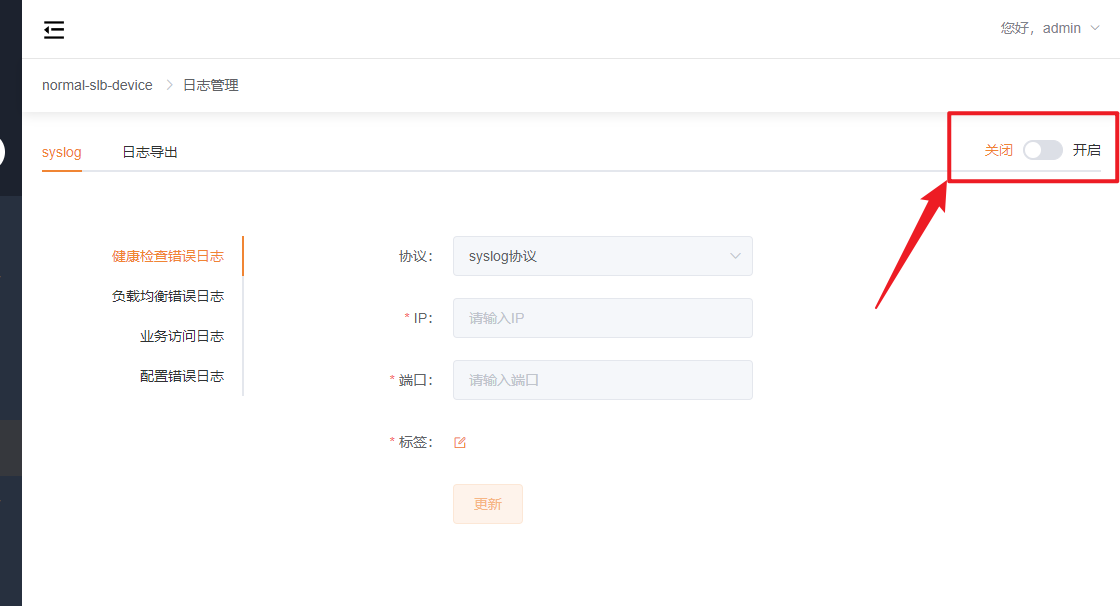
| 配置项 | 说明 |
|---|---|
| Syslog 开关 | 开启后日志以 Syslog 协议外发,同时内置日志中心不再记录 |
| 日志类型 | 四类可选:健康检查错误日志、负载均衡错误日志、业务访问日志、配置错误日志 |
| 协议/ IP / 端口 | Syslog 服务器地址和接收端口 |
| 标签(Tag) | 自定义标签,如 engine-A-n6,用于在外部日志平台区分来源 |
自定义上报字段
对于业务访问日志,可以按需配置上报字段项和字段名称,避免上报无用字段浪费带宽和存储。
开启 Syslog 外发后,内置日志中心的图形化分析功能不再可用。两种方式互斥,按需选择。
排障实战:用日志定位问题的典型流程
场景一:用户反馈"访问网站返回 502"
排查步骤:
- 进入目标虚拟服务详情 → 日志标签
- 时间范围设为用户反馈的时间段
- 按 HTTP 状态码过滤 → 查看 502 请求
- 点击其中一条 502 日志的"详情",查看"服务器节点"字段 → 确认是哪个后端节点返回了 502
- 进入该节点的【分析】页面 → 查看该时间段是否健康检查异常(可能节点已被标记为下线)
- 查看"响应时长"字段 → 如果超长,可能是后端处理超时导致
- 如果开启了"记录全部 HTTP 头部":检查请求头部是否完整、后端返回的响应头部有无异常
场景二:新版本上线后错误率上升
排查步骤:
- 进入虚拟服务日志 → HTTP 状态码全景视图
- 对比上线前后的状态码分布变化(如 200 从 99% 降到 85%)
- 点击增长的状态码(如 500),钻取到具体日志列表
- 按 URI 分组查看 → 是某个特定接口返回 500,还是全面出现?
- 查看"分发规则"字段 → 确认灰度/金丝雀策略是否按预期路由到了新版服务器池
- 查看"服务器节点"和"服务器池"字段 → 确认请求是否被路由到了正确版本的后端
场景三:移动端用户反馈"页面白屏",PC 端正常
排查步骤:
- 切换到"设备"全景视图 → 确认移动端流量占比是否正常
- 切换到"浏览器"视图 → 查看是否有特定浏览器(如旧版 iOS Safari)的请求
- 切换到"操作系统"视图 → 查看 iOS/Android 版本的分布
- 在日志列表中按设备类型或 User-Agent 过滤,查看移动端请求的 HTTP 状态码和响应包体大小
- 如果响应包体大小为 0 或异常小 → 可能后端对移动端 User-Agent 返回了空响应
- 如果开启"记录全部 HTTP 头部":检查移动端请求的 Accept、Content-Type 等头部是否与 PC 端不同
场景四:AI 大模型接口调用成本异常增长
排查步骤:
- 进入 AI 虚拟服务日志 → Token 消耗统计
- 查看提示词 Token 和生成 Token 的趋势曲线,判断是哪类 Token 增长了
- 输入 Token 单价,计算实际金额消耗
- 切换到"模型访问量"桑基图 → 查看是否有请求被意外路由到了高成本模型
- 切换到"结束原因"环形图 → 如果"Stop"之外的原因显著增多(如大量超时),说明有请求在消耗 Token 但未完成
- 切换到"模型推理组访问时延" → 如果 P95/P99 时延显著升高,可能导致用户频繁重试(重试 = 重复消耗 Token)
场景五:怀疑某个 IP 在恶意刷接口
排查步骤:
- 切换到"客户端地址"全景视图 → 查看 Top IP 列表
- 如果某个 IP 访问量远超其他 → 点击该 IP 进入过滤视图
- 查看该 IP 的请求 URI 分布 → 是否集中在某个接口
- 查看该 IP 的请求频率 → 在日志列表中按时间排序,确认是否为机器行为
- 确认后,可通过 IP 集合管理 将该 IP 加入黑名单
日志相关限制与注意事项
- 免费版不支持日志功能,包括日志中心和 Syslog 外发。
- 日志中心与 Syslog 互斥:开启 Syslog 后日志中心不再记录。
- 每秒上报日志数是关键保护机制,超出部分静默丢弃。如果日志中"缺了一些请求",可能是阈值设低了。
- 记录全部 HTTP 头部会增加每条日志的数据量和转发引擎的 CPU 开销,不建议全量开启。建议仅在排查特定问题时临时开启。
- AI 虚拟服务的日志字段比普通虚拟服务更多(AI 大模型日志字段),日志存储和查询开销更大。
- 默认查询条数为 1000 条,过大的查询数量会影响查询速度,建议缩小时间范围或增加过滤条件。