健康检查配置指南
健康检查解决了什么问题
负载均衡的目标是把流量分给"活着的"后端服务器。但"端口开着"不等于"服务正常"——进程可能假死、数据库连接池可能耗尽、接口可能开始返回 500。健康检查就是持续探测每个后端节点,自动把异常节点踢掉,恢复正常后再加回来。
如果没有健康检查,负载均衡会把请求持续发给已经挂掉的节点,用户看到的就是随机出现的 502/504 错误。
健康检查在哪里执行
这是一个关键问题:健康检查由转发引擎执行,而非管理节点。
服务器池绑定了 engine-A 和 engine-B
└── engine-A 对其负责的节点执行健康检查(每台节点独立探测)
└── engine-B 对其负责的节点执行健康检查(每台节点独立探测)这意味着:
- 如果服务器池绑定了多个转发引擎,每个引擎都独立对节点做健康检查
- 某台引擎判定节点不健康,仅停止该引擎向该节点转发流量,不影响其他引擎
- 节点健康状态会汇总显示在控制台的服务器池列表中(绿色=全部健康,黄色=部分异常,红色=全部不可用)
基本配置 vs 高级配置
健康检查有两个配置层级。区别在于"上线"和"下线"是否使用同一套参数。
基本配置(简单场景)
| 参数 | 含义 | 默认值建议 |
|---|---|---|
| 超时时间 | 等待节点响应的最长时间 | 3~5 秒 |
| 间隔时间 | 两次探测之间的间隔 | 5~10 秒 |
| 最大连续尝试次数 | 连续成功 N 次判定为"上线",连续失败 N 次判定为"下线" | 3 次 |
基本配置的局限: 上线和下线使用相同的间隔、超时和次数。这意味着节点恢复上线和检测到故障下线的速度是一样的。
高级配置(生产环境推荐)
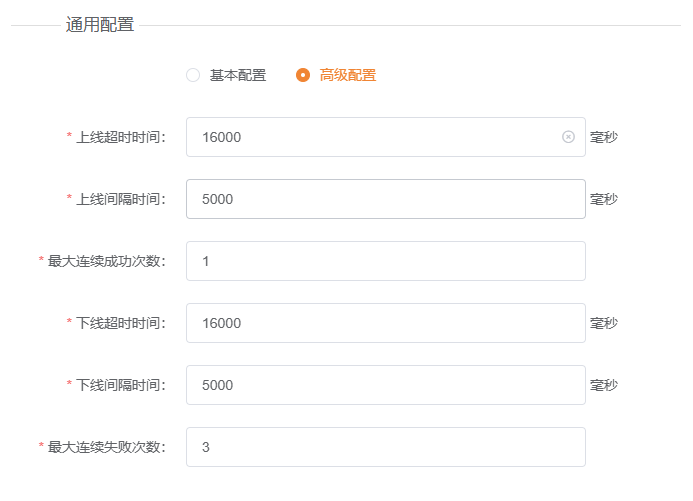
高级配置允许上线和下线分别设置,实现"快下线、慢上线"的策略——这对生产稳定性至关重要:
| 参数 | 推荐配置 | 原因 |
|---|---|---|
| 下线超时/间隔 | 较短(如超时 2s,间隔 3s) | 故障要快速发现,减少"发给故障节点的请求数" |
| 上线超时/间隔 | 较长(如超时 10s,间隔 10s) | 恢复要谨慎确认,避免抖动节点反复上下线 |
| 连续失败次数 | 2~3 次 | 偶发超时不等于节点故障,连续失败才确认 |
| 连续成功次数 | 3~5 次 | 偶发恢复正常不等于稳定,需多次确认 |
为什么"快下线、慢上线"很重要
假设一个节点因为瞬时 CPU 飙高导致健康检查超时了 1 次。如果上下线使用相同参数(如 2 次失败就下线),它很快就下线了;恢复后很快又上线了。如果节点反复抖动,就会不断上下线——这就是"震荡"。高级配置让下线快(快速止损)、上线慢(确认稳定后再加入),能有效防止震荡。
免费版不支持高级配置。
服务器池上多个健康检查的行为
一个服务器池可以绑定多个健康检查策略。多个策略之间存在协作关系:
AND 关系(全部通过才算健康)
所有策略都判定节点健康时,节点才算健康。任意一个策略判定失败,节点即下线。
适用场景: 需要同时满足多层检查。例如既要端口通(TCP),又要接口返回 200(HTTP),还要业务逻辑正确(自定义脚本)。
策略 1:TCP 端口检查 → 通过 ✓
策略 2:HTTP /health 返回 200 → 通过 ✓
策略 3:自定义脚本检查业务逻辑 → 通过 ✓
→ 节点判定为健康OR 关系(任一通过即算健康)
只要有一个策略判定节点健康,节点就算健康。
适用场景: 服务有多种健康检查方式,但只需一种方式能通就算正常。例如同时监听了 HTTP 和 gRPC 两个端口,只要有一个端口能正常响应,服务就算可用。
策略 1:HTTP /health 返回 200 → 通过 ✓
策略 2:gRPC 健康检查 → 失败 ✗
→ 节点判定为健康(策略 1 通过了)如何选择
| 场景 | 推荐 | 示例 |
|---|---|---|
| 常规 Web 服务 | AND | TCP 端口 + HTTP /health |
| 多协议服务(同节点) | OR | HTTP 或 gRPC,任一能通即可 |
| 关键业务 | AND(多维度) | TCP + HTTP + 自定义脚本(检查数据库连接池等) |
| 简单心跳 | 单策略 | ICMP Ping 即可 |
如何选择健康检查协议
用户手册列出了 20+ 种协议,以下是按场景快速选型的指南:
| 你的后端服务 | 推荐协议 | 原因 |
|---|---|---|
| 普通 Web 服务(HTTP) | HTTP | 能检查到"端口通但业务返回 500"的情况 |
| HTTPS 服务 | HTTPS | 同 HTTP,额外支持 SNI |
| 纯 TCP 服务(不涉及 HTTP) | TCP 或 TCP 半连接 | TCP 半连接更轻量(收到 SYN-ACK 就 RST,不完成握手) |
| 仅需确认主机存活 | ICMP | 等同于 Ping |
| UDP 服务(DNS、视频流等) | UDP | 发送探测报文,根据是否有响应或报错判断 |
| 数据库(MySQL/PostgreSQL/Oracle 等) | 对应的数据库协议 | 能验证到"端口通但数据库不响应查询"的情况 |
| DNS 服务器 | DNS | 发送 DNS 查询,验证解析结果 |
| AI 大模型推理服务 | OpenAI-API-Compatible | 专为 AI 场景设计,支持 /v1/models 等 API 检查 |
| 以上都不满足 | 自定义脚本 | Python 脚本,完全自定义逻辑 |
分层检查建议
最简单的做法是先用 ICMP 或 TCP 做一层快速探活,再叠加 HTTP 或数据库协议做应用层检查。分层的好处是:ICMP/TCP 间隔可以短(快速发现网络故障),应用层检查间隔可以长(减少对后端服务的请求压力)。
常见配置场景
场景一:标准 HTTP 服务健康检查
需求:后端是 Nginx/SpringBoot HTTP 服务,有一个 /health 端点。
协议:HTTP
端口:复用监听端口(使用服务器池中配的端口)
HTTP 方法:GET
请求路径:/health
响应码:200
高级配置:
下线超时 2s,下线间隔 3s,连续失败 2 次
上线超时 5s,上线间隔 10s,连续成功 3 次场景二:TCP 端口快速探活 + HTTP 业务检查
需求:先确认端口通,再确认接口返回正常。
策略 1(TCP):端口复用监听端口
策略 2(HTTP):GET /api/health,响应码 200、204 都算健康
多策略关系:AND场景三:数据库健康检查
需求:MySQL 数据库,不仅端口要通,还要能执行查询。
协议:MYSQL
数据库名称:your_db
用户名:health_check_user
密码:***
内容验证:开启
查询 SQL 语句:SELECT 1
查询结果:1注意:生产环境中应为健康检查专门创建一个低权限的数据库用户,避免使用 root 账号。
自定义脚本(高级)
当内置协议无法满足需求时(如需要检查服务内部状态、调用另一个服务的结果来判断健康等),可以使用自定义脚本(采用类GO语言的语法)。
脚本工作原理
- 脚本部署在转发引擎上,由转发引擎调用执行
- 脚本接收 2 个参数:
节点IP和节点端口 - 脚本
return true表示健康,return false表示不健康 - 脚本中有 2 个全局变量可直接使用:
curIp(当前节点 IP)、curPort(当前节点端口)
内置函数
| 函数 | 作用 | 用法 |
|---|---|---|
httpReq(url, method, body) | 发送 HTTP 请求 | 返回 (状态码, HTTP状态码) |
tcpConnect(ip, port) | TCP 连接测试 | 返回状态码,0 = 成功 |
icmpConnect(ip) | ICMP Ping | 返回状态码,0 = 成功 |
getNodeStatus(poolId, nodeIp, nodePort) | 查询另一服务器池中某节点的健康状态 | 返回 (状态码, 健康状态字符串) |
简单示例:HTTP 健康检查
var codeHttp int
var statusCode int
var url string
url = "http://" + curIp + ":" + intToString(curPort) + "/health"
codeHttp, statusCode = httpReq(url, "GET", "")
if codeHttp == 0 && statusCode == 200 {
return true
}
return false进阶示例:关联健康检查
场景:节点 A 的健康状态依赖于另一服务器池"共享服务池"中某节点的状态。这在微服务架构中很常见——如果依赖的上游服务挂了,本节点即使进程正常也应标记为不健康。
var code int
var status string
# 检查依赖的上游服务是否健康
code, status = getNodeStatus("共享服务池", "10.133.7.250", 12000)
if code == 0 && status == "health" {
# 上游服务健康,再检查本节点
code = icmpConnect(curIp)
if code == 0 {
return true
}
}
return false更多脚本示例(条件判断、循环、变量定义等)参见 健康检查用户手册 - 自定义脚本。
常见问题与调试
Q:节点一直显示"检查中"怎么办?
节点加入服务器池后首次健康检查需要几个周期(间隔 × 尝试次数)才能出结果。比如间隔 5 秒、连续成功 3 次,至少需要 15 秒才能变为"健康"。如果长时间卡在"检查中":
- 确认转发引擎与节点之间网络可达(从转发引擎上 ping 节点 IP)
- 确认健康检查端口与节点实际监听端口一致
- 检查防火墙/安全组是否放行了健康检查端口
Q:节点频繁上下线(震荡)怎么处理?
- 开启高级配置,将上线参数设置得比下线参数更宽松(上线间隔更长、上线连续成功次数更多)
- 检查节点的 CPU/内存是否有周期性飙高
- 如果使用的是 TCP 半连接,改为 TCP 完整连接或 HTTP 深度检查
Q:健康检查策略能修改后立即生效吗?
修改健康检查策略后,引用该策略的所有服务器池会自动应用新配置,无需重启或变更执行。但已建立的 TCP 连接不会中断。
Q:自定义脚本执行超时怎么办?
脚本有默认执行超时限制。如果脚本逻辑复杂(如需要调用多个外部服务),建议优化脚本逻辑或拆分为多个简单策略(AND 组合),而不是在一个脚本中完成所有检查。
各协议健康检查的完整字段说明参见 健康检查用户手册。