部署AI网关
部署带有 Fallback(故障回退) 功能的 AI 网关主要分为两个核心阶段:
构建后端算力池:定义并校验后端大模型(LLM)推理组的可用性。确保“服务器池列表”中对应的资源状态显示为绿色。
发布虚拟服务:创建面向客户端的统一入口。客户端只需将原有的后端大模型 IP 端口替换为虚拟服务的监听地址,即可实现透明的流量接管与智能容灾。
配置后端LLM大模型
定义健康检查策略
针对 openai-api-compatible 类型的健康检查,需根据推理环境动态调整探测逻辑:
检查类型二选一:必须在“存活检查(L7 连通性)”与“模型就绪检查(模型加载状态)”中至少选择一项。
多推理框架适配:若后端混合部署了 Ollama、vLLM 等不同引擎,其 API 路径(如 /v1/models 或 /api/tags)不一致,应勾选 “跟随模型访问策略中的协议” 以实现自动适配。
模型名称动态校验:若开启“模型就绪检查”,系统将验证推理组是否已加载指定模型。
模糊匹配:模型名称支持包含关系。
动态策略驱动:若不同推理组承载的模型名称不同,请勾选 “校验模型访问策略中配置的模型名称”。
频率调优:大模型推理对算力消耗极大,健康检查间隔不宜过频,以免影响正常业务。详细参数请参考 配置健康检查
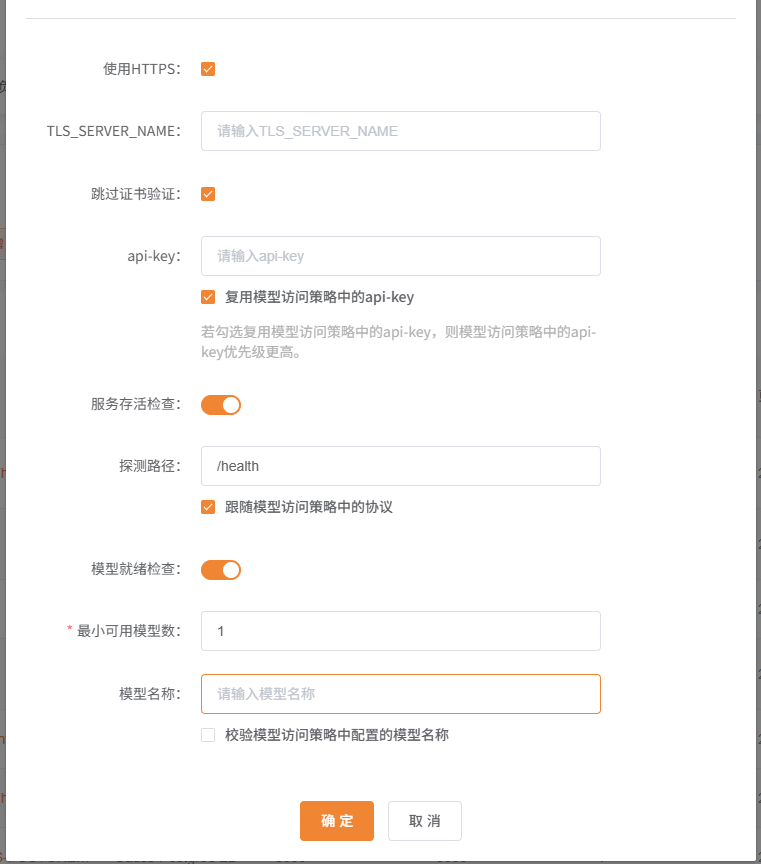
添加模型访问策略
模型访问策略决定了网关如何“改写”或“透传”发往后端推理组的请求。 
参数覆盖原则:策略中的非必填项若留空,网关将透传客户端请求中的参数;若填写,则网关会强行覆盖请求参数。
典型应用:Fallback 场景下的异构模型替换
场景实例:客户端请求的目标是 qwen3:32b,由推理组 A 提供服务。
故障切换:当推理组 A 宕机,网关自动将请求切换至备份推理组 B(模型为 glm5:32b)。
自动修补:由于后端模型名称不一致,必须在推理组 B 的“模型访问策略”中将模型名称强制配置为 glm5:32b。这样,网关在转发时会自动修正请求体,确保备份节点能正确响应。
模型访问策略定义了访问某一个模型推理组的方式,如下图所示:
添加大模型后端服务器池
在创建服务器池时,需开启 “AI 模式”,系统将自动激活模型推理组配置面板。 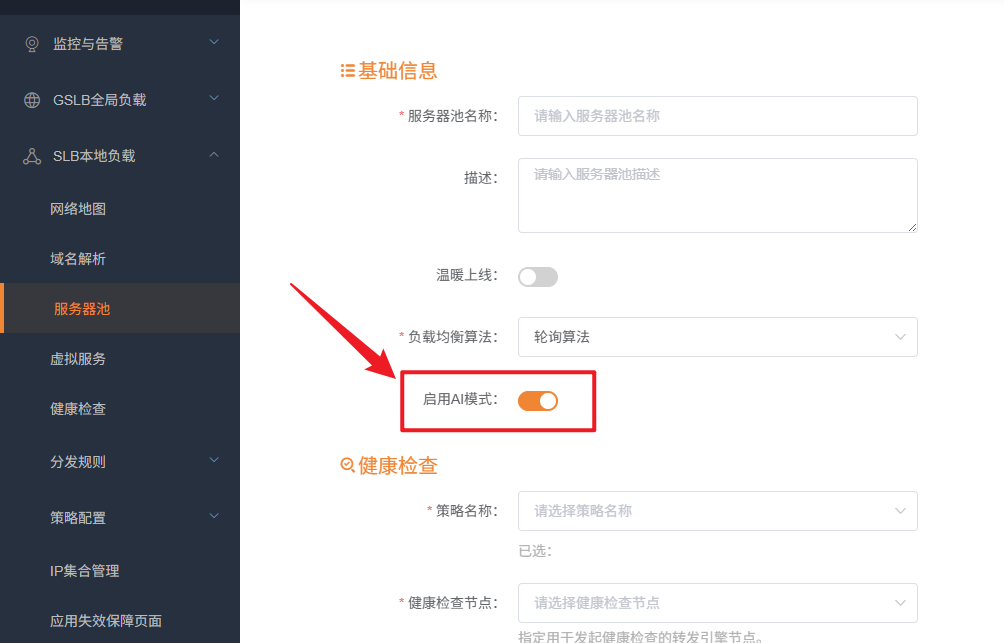 在完成健康检查策略、负载均衡算法等基础参数设定后,可根据业务需求添加多个模型推理组。其核心调度逻辑如下:
在完成健康检查策略、负载均衡算法等基础参数设定后,可根据业务需求添加多个模型推理组。其核心调度逻辑如下:
成员与配置单位
- 每个推理组可关联多个服务器节点(支持 IP、端口及权重配置)。通常一个大模型实例对应一个监听地址。
策略共享机制
- 每个推理组需绑定一个“模型访问策略”,组内所有服务器节点将共用该策略进行请求改写或透传。
优先级调度(Fallback 核心)
逻辑:优先级数字越大,等级越高。
行为:网关接收请求后,会自动筛选当前健康的推理组并按优先级排序,流量将优先流向等级最高的推理组。
等价路由均衡
逻辑:当存在多个优先级相同的健康推理组时。
行为:系统将依据预设的负载均衡算法(如轮询、加权最小连接数),结合各节点权重进行流量分发。
配置对客户端提供AI访问的虚拟服务
配置模型转发策略
模型转发策略侧重于对 提示词(Prompt) 的二次加工与安全治理:
提示词增强:支持模板填充,可在请求原有的提示词前后统一插入预设内容(如系统级指令或 Context 增强)。
内容合规审查:内置黑白名单过滤机制,支持正则表达式,实现对敏感提示词的实时拦截或清洗。
配置虚拟服务
在虚拟服务配置流程中(其余步骤与标准业务一致),需执行以下关键操作:
启用 AI 引擎:开启“启用 AI 模式”开关。
定义处理逻辑:在“处理方式”中选择 “HTTP代理”或者“HTTPS代理”。
关联算力池:在服务器池选项中,指定上一步创建的“AI 模式服务器池”。
创建完成后,点击“变更执行”即完成。